
关于iOS开发中内存管理的知识脉络,我依据自己的思路整理了一下,根据管理的是哪个区域的内存->管理的方式->内存泄露->内存警告线索来展开。具体的每个步骤里面会有更多的关联知识点,但是能力有限,写作匆忙,有瑕疵错误的地方,多多包涵。
内存分区
内存区域划分
程序如果想要执行,第一步就需要从磁盘加载到内存中。运行过程中内存的分区是怎样的呢,如下图所示。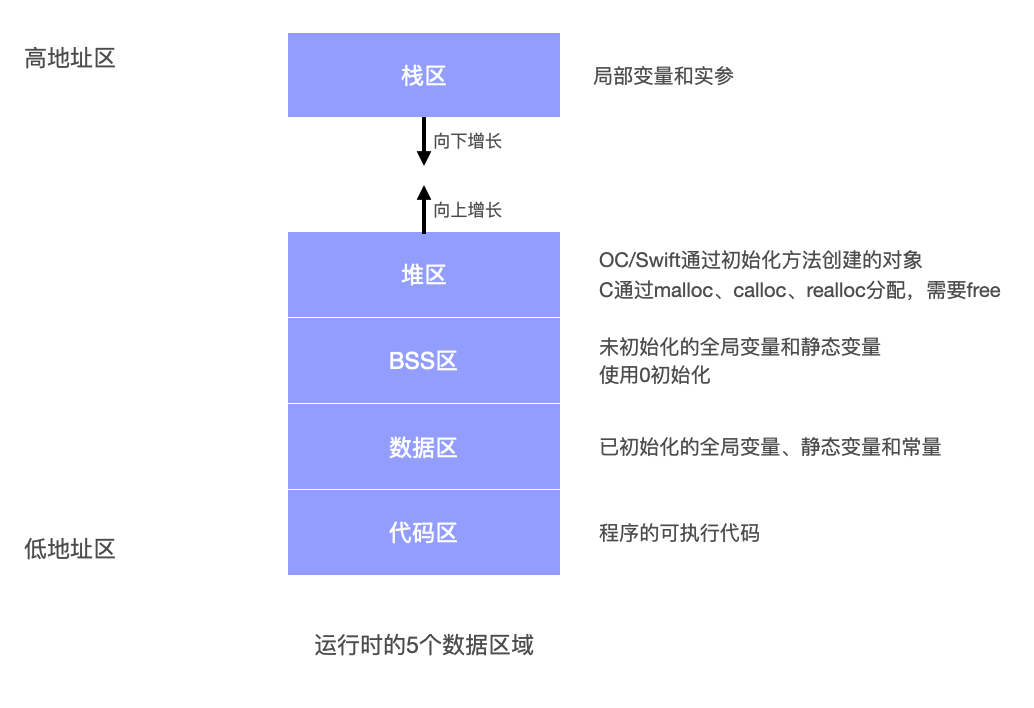
1,栈区(stack)由编译器自动分配并释放的变量存储区。存放函数的参数值,局部变量等。栈是系统数据结构,对应线程/进程是唯一的。优点是快速高效,缺点是有限制,数据不灵活。[先进后出]
2,堆区(heap)由程序员申请和释放,如果程序员不释放,程序结束时,会由OS回收,比如在iOS中alloc都是存放在堆中。优点是灵活方便,数据适应面广泛,但是效率有一定降低。
3,BSS区 全局变量和静态变量的存储是放在一起的,存放未初始化的全局变量和静态变量的区域,程序结束后有系统释放。
4,数据区 存放初始化的全局变量和静态变量的区域,程序结束后由系统释放。
5,代码区 存放函数的二进制代码,程序结束后由系统释放。
堆和栈的区别
- 管理方式:堆空间的申请释放工作由程序员控制,容易产生内存泄漏。而栈是由编译器自动管理,无需我们手工控制。
- 空间大小:堆是向高地址扩展的数据结构,是不连续的内存区域。因为系统是用链表来存储空闲内存地址的,且链表的遍历方向是由低地址向高地址,堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间较灵活,也较大。栈是向低地址扩展的数据结构,是一块连续的内存区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,当申请的空间超过栈的剩余空间时,将提示溢出。因此,用户能从栈获得的空间较小。
- 内存碎片:对于堆来讲,频繁的malloc/free(new/delete)势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低(虽然程序在退出后操作系统会对内存进行回收管理)。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出。
- 分配方式:堆都是动态分配的。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloc函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
- 分配效率:栈由系统自动分配,速度较快,不会产生内存碎片。但程序员是无法控制的。堆是由alloc分配的内存,速度比较慢,而且容易产生内存碎片,不过用起来最方便。
- 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
由以上的内存分区知识点可知,堆区内存是由程序员管理,其他区域全部是由编译器自动管理。所以iOS开发过程中管理的是堆区内存。
引用计数
iOS开发,不管是Objective-C语言还是Swift语言,其内存管理的方式都是基于引用计数的。本段博文就是讲解引用计数的原理及特点。
Objective-C和Swift语言内存管理的方式是引用计数,Java和C#语言的内存管理方式是GC垃圾回收机制(Garbage Collection)
什么是引用计数、引用计数原理
引用计数(Reference Count)是一种简单有效的管理对象生命周期的方式。它的原理是:当我们创建一个新对象的时候,它的引用计数为1,当有一个新的指针指向该对象时,我们把其引用计数加1,当某个指针不再指向该对象时,我们将其引用计数减1,当对象的引用计数为0的时候,说明不再被任何指针引用了,我们可以将对象销毁,回收内存。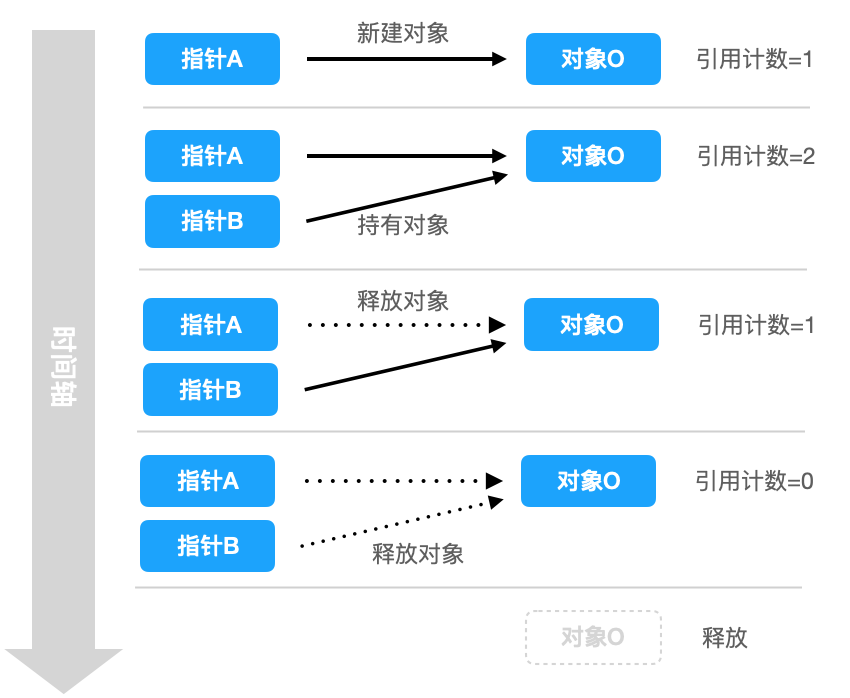
引用计数的分类
1,手动引用计数
手动引用计数(Manual Reference Count,简称MRC),在此模式下,对象的生命周期需要开发者手动调用retain,release等方法去管理。
运行以下代码,可以通过log看到引用计数的变化。
1 | - (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions { |
运行结果如下:
Reference Count = 1
Reference Count = 2
Reference Count = 1
上述代码中NSObject实例的retainCount属性、retain和release方法只在MRC的模式下才能够调用。现在新建的工程默认都是ARC模式,允许以文件为单位关闭ARC模式,开启MRC模式。具体方法就是通过编译列表找到目标文件,在文件后面加上-fno-objc-arc的编译参数即可。
2,自动引用计数
自动引用计数(Automatic Reference Count,简称ARC),是苹果在WWDC 2011大会上提出的用于管理内存的技术。在此模式下,编译器会自动添加内存管理的方法,让开发者从繁琐的内存管理中解放出来。
过度依赖ARC问题
1.ARC技术能够解决iOS开发中90%的内存管理问题,但是另外10%是需要开发者自己处理的。这主要与底层Core Foundation对象交互的那部分,因为Core Foundation对象不在ARC的管理范畴,所以需要开发者去维护这些对象的引用计数。
2.没有正确使用Block导致的循环引用的问题。
如果过度依赖ARC,不了解引用计数原理,那面对以上两种情况,会显得一筹莫展。
3,Core Foundation对象内存管理
底层Core Foundation对象,大多数以XxxCreateWithXxx形式创建。例如
1 | // 创建一个CFStringRef对象 |
对于这些对象引用计数的修改,要相应的使用CFRetain和CFRelease方法。
1 | // 引用计数加1 |
CFRetain和CFRelease方法,我们直观的认为,它们与Objective-C中的retain和release方法等价。
除此之外,还有另外一个问题需要解决。在ARC下,有时候需要将一个Core Foundation对象转换成一个Objective-C对象,这个时候我们需要告诉编译器,转换过程中引用计数需要如何调整。这就引入了与bridge相关的关键字,以下是这些关键字的说明:
- __bridge 只做类型转换,不修改相关对象的引用计数,原来的Core Foundation对象在不用时,需要调用CFRelease方法。
- __bridge_retained 类型转换后,将相关对象的引用计数加1,原来的Core Foundation对象在不用时,需要调用CFRelease方法。
- __bridge_transfer 类型转换后,将该对象的引用计数交给ARC管理,原来的Core Foundation对象在不用时,不需要调用CFRelease方法。
根据具体业务逻辑,合理使用上面三种转换关键字,就可以解决Core Foundation对象与Objective-C对象相对转换的问题了。
引用计数的优点
简单有效。
为什么需要引用计数?在没有引用计数的情况下,一般内存管理的原则是“谁申请谁释放”,假如对象A生成了一个对象M,需要调用对象B,将对象M作为参数传递过去。那么对象A就需要在对象B不再需要对象M的时候,将对象M销毁。但是对象B可能只是临时用一下对象M,也可能觉得对象M很重要,将它设置成自己的一个成员变量,在这种情况下,什么时候销毁对象M就成了一个难题。
对于这种情况,有一个暴力的做法,就是对象A在调用完对象B之后,马上就销毁参数对象M,然后对象B需要将参数另外复制一份,生成另一个对象M2,然后自己管理对象M2的生命期。但是这种做法有一个很大的问题,就是它带来了更多的内存申请、复制、释放的工作。本来一个可以复用的对象,因为不方便管理它的生命期,就简单的把它销毁,又重新构造一份一样的,实在太影响性能。
还有另外一种方法,就是对象A在构造完对象M之后,始终不销毁对象M,由对象B来完成对象M的销毁工作。如果对象B需要长时间使用对象M,就不销毁它,如果只是临时用一下,则可以用完后马上销毁。这种做法看似很好的解决了对象复制的问题,但是它强烈依赖于A、B两个对象的配合,代码维护者需要明确地记住这种编程约定。而且,由于对象M的申请是在对象A中,释放在对象B中,使得它的内存管理代码分散在不同对象中,管理起来也非常费劲。如果这个时候情况再复杂一些,例如对象B需要向对象C传递对象M,那么这个对象在对象C中又不能让对象C管理。所以这种方式带来的复杂性更大,更不可取。
所以引用计数很好地解决了这个问题,在参数M的传递过程中,哪些对象需要长时间使用这个对象,就把它的引用计数加1,使用完了之后再把引用计数减1。所有对象都遵守这个规则的话,对象的生命期管理就可以完全交给引用计数了。我们也可以很方便的享受到共享对象带来的好处。
引用计数的缺点
引用计数这种管理内存的方式虽然简单有效,但是有一个比较大的瑕疵,就是它不能很好的解决循环引用的问题。
如下图所示对象A和对象B,相互引用对方作为自己的成员变量,只有自己销毁时,才会将成员变量的引用计数减1。因为对象A的销毁依赖于对象B的销毁,而对象B的销毁又依赖于对象A的销毁,这样就造成了循环应用(reference cycle)的问题。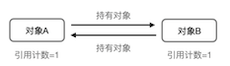
实际项目中不止两个对象存在循环引用问题,多个对象间依次持有,形成一个环状,也会造成循环引用,而且环状越大越难发现。
解决方式:1.明确知道这里会存在循环引用,在合理的位置主动断开环中的一个引用。2.弱应用的办法。弱引用虽然持有对象,但是并不增加引用计数。